

In this post, we focus on a Content Library operation, namely synchronization, with the goal of providing guidelines. We also cover two Content Library maintenance operations: import and export.
Library synchronization
After you crate and publish a library, you can share its content between different vCenters by using the synchronization operation, which clones a published library by downloading all the content to a subscribed library.
We tested multiple scenarios based on vCenter connectivity and backing storage configurations. In the following sections, we discuss each scenario in detail after a brief description of the experimental testbed.
Experimental testbed
For our experiments, we used a total of four ESX hosts: two for the vCenter appliances (one for the published library and a second for the subscribed library) and two to provide the datastore backing for the libraries. Each vCenter separately managed these two hosts.
ESX hosts running vCenter Server Appliance – 2 Dell PowerEdge R910 servers with the following:
- CPUs: Four 6-core Intel® Xeon® E7530 @1.87 GHz, Hypert-Threading enabled
- Memory: 80GB
- Virtualization platform: VMware vSphere 6.0 with 16 vCPU and 32GB RAM
ESX hosts providing datatastore backing – 2 Dell PowerEdge R610 servers with the following:
- CPUs: Two 4-core Intel® Xeon® E5530 @2.40 GHz, Hyper-Threading enabled
- Memory: 32GB
- Virtualization platform: VMware vSphere 6.0
- Storage adapter: QLogic ISP2532 DualPort 8Gb Fibre Channel HBA
- Network adapters:
- QLogicNetXtreme II BCM5709 1000Base-T (data rate: 1Gbps)
- Intel Corporation 82599EB 10-Gigabit SFI/SFP+ (data rate: 10Gbps)
Storage array: EMC VNX5700 exposing two 20-disk RAID-5 LUNS with a capacity of 12TB each
Single-item library synchronization
When multiple vCenters are part of the same SSO domain, they can be managed as a single entity. This feature is called Enhanced Linked Mode. In an environment where Enhanced Linked Mode is available, the contents of a published library residing under one vCenter can be synched to a subscribed library residing under another vCenter by directly copying the files from the source datastore to the destination datastore (this is possible provided that the ESX hosts connected to those datastores have direct network connectivity).
When Enhanced Linked Mode is not available, the contents of a published library must be streamed through the Content Library transfer service components residing on each vCenter. In this case, three scenarios exist based on the storage configuration:
- Both published and subscribed libraries reside on a datastore.
- Both published and subscribed libraries reside on an NFS file system mounted on the vCenters.
- The published library resides on an NFS file system, while the subscribed library resides on a datastore.
These four scenarios (Enhanced Linked Mode and the three scenarios without it) are depicted in figure 1 below.
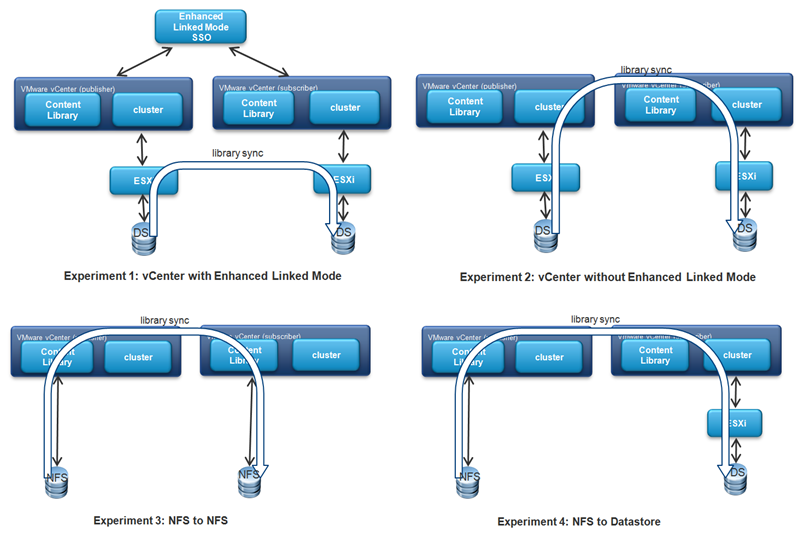
Figure 1. Library synchronization experimental scenarios and related data flows.
For each of these, we synchronized the contents of a published library to a subscribed library and measured the completion time of this operation. The published library contained only one item, a 5.4GB OVF template containing a Red Hat virtual machine in compressed format (the uncompressed size is 15GB). The following summarizes the four experiments:
- Experiment 1: The published and subscribed libraries resided under different vCenters with Enhanced Linked Mode; both libraries were backed by datastores.
- Experiment 2: The published and subscribed libraries resided under different vCenters without Enhanced Linked Mode; both libraries were backed by datastores.
- Experiment 3: The published and subscribed libraries resided under different vCenters without Enhanced Linked Mode; both libraries were backed by NFS file systems, one mounted on each vCenter.
- Experiment 4: The published and subscribed libraries resided under different vCenters without Enhanced Linked Mode; the published library was backed by an NFS file system, and the subscribed library was backed by a datastore.
For all the experiments above, we used both 1GbE and 10GbE network connections to study the effect of network capacity on synchronization performance. In the scenarios of experiments 2 through 4, we used the transfer service to stream data from the published library to the subscribed library. This service leveraged a component in vCenter called rhttpproxy. Its purpose was to offload the encryption/decryption of SSL traffic from the vCenter web server (see figure 2). To study the performance impact of data encryption/decryption in those scenarios, we ran the experiments twice, the first time with rhttpproxy enabled (default case), and the second time with rhttpproxy disabled (thus reducing security by transferring the content in the clear).
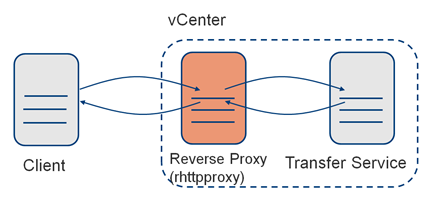
Figure 2. Reverse HTTP proxy
Single-item library synchronization results
The results of the experiments outlined above are shown in figure 3 and summarized below.
- Experiment 1: The datastore-to-datastore with Enhanced Linked Mode scenario was the fastest of the four, with a sync completion time of 105 seconds (1.75 minutes). This was because the data path was the shortest (the two ESX hosts were directly connected) and there was no data compression/decompression overhead because content on the datastores was stored in uncompressed format. When we used a 10GbE network, the library sync completion time was significantly shorter (63 seconds). This suggests that the 1GbE connection between the two hosts was a bottleneck for this scenario.
- Experiment 2: The datastore-to-datastore without Enhanced Linked Mode scenario was the slowest, with a sync completion time of 691 seconds (more than 11 minutes). This was because the content needed to be streamed via the transfer service between the two sites, and it also incurred the data compression and decompression overhead across the network link between the two vCenters. Using a 10GbE network in this scenario had no measurable effect because most of the overhead came from data compression/decompression. Also, disabling rhtpproxy hasd a marginal effect for the same reason.
- Experiment 3: The NFS file system to NFS file system scenario was the second fastest with a sync completion time of 274 seconds (about 4.5 minutes). Although the transfer path had the same number of hops as the previous scenario, it did not incur the data compression and decompression overhead because the content was already stored in a compressed format on the mounted NFS file systems. Using a 10GbE network in this scenario led to a substantial improvement in the completion time (more than halved). An even more significant improvement was achieved by disabling rhtpproxy. The combined effect of these two factors yielded a 3.7x reduction in the synchronization completion time. These results imply that, for this scenario, both the 1GbE network and the use of HTTPS for data transfer were substantial performance bottlenecks.
- Experiment 4: The NFS file system to datastore was the third fastest scenario with a sync completion time of 298 seconds (just under 5 minutes). In this scenario, the transfer service at the subscribed vCenter needed to decompress the files (content on mounted NFS file systems was compressed), but the published vCenter did not need to re-compress them (content on datastores was stored uncompressed). Since data decompression had a substantially smaller overhead than compression, this scenario achieved a much better performance than Experiment 2. Using a 10GbE network and disabling rhttpproxy in this scenario had the same effects as in Experiment 3 (that is, a 3.7x reduction in completion time).
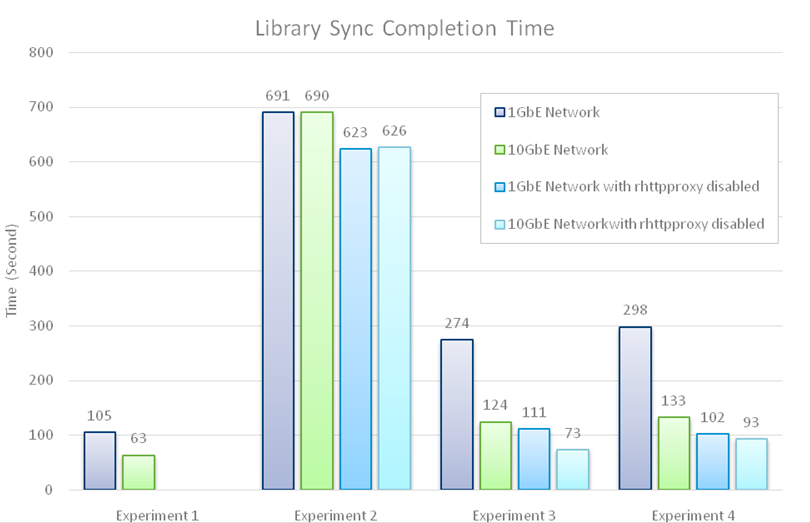
Figure 3. Library synchronization completion times.
The above experiments clearly show that there are a number of factors affecting library synchronization performance:
- Type of data path – direct connection vs. streaming
- Network capacity
- Data compression/decompression
- Data encryption/decryption
The following recommendations translate these observations into a set of actionable steps to help you optimize Content Library synchronization performance:
- You can obtain the best performance if Enhanced Linked Mode is available and both the published and subscribed libraries are backed by datastores.
- When Enhanced Linked Mode is not available, avoid datastore-to-datastore synchronization. If no other optimization is possible, place the published library on an NFS file system (notice that for best deployment performance the subscribed library/libraries should be backed by a datastore.
- Using a 10GbE network is always beneficial for synchronization performance (except in the datastore-to-datastore synchronization without Enhanced Linked Mode).
- If data confidentiality is not required, the overhead of the HTTPS transport can be avoided by disabling rhttpproxy as described in KB 320226.
Concurrent library synchronization
To assess the performance of a concurrent library synchronization operation where multiple items are copied in parallel, we devised an experiment where a subscribed library was synchronized with a published library that contained an increasing number of items from 1 to 10. The source and destination vCenters supported Enhanced Linked Mode and the two libraries were backed by datastores. Each item had an OVF template containing a Windows virtual machine with a 41GB flat VMDK file. Each vCenter managed one cluster with two ESX hosts, as shown in figure 4.
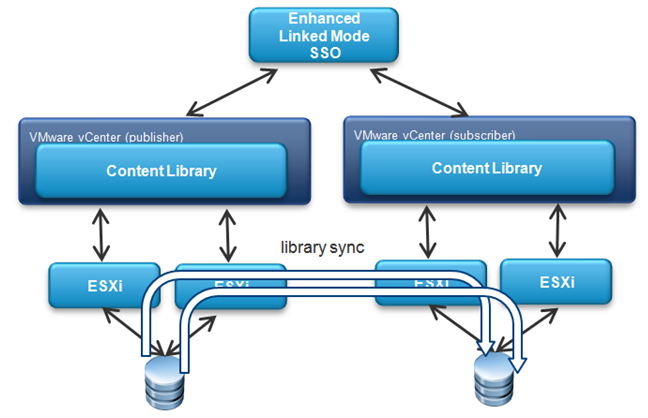
Figure 4. Concurrent library synchronization
Concurrent library synchronization results
We studied two scenarios depending on the network speed. With a 1GbE network, we observed that each file transfer always saturated the network bandwidth between the two ESX hosts, as we expected. Because each site had two ESX hosts per vCenter, the library synchronization could use two pairs of ESX hosts for transferring two files concurrently.
As shown by the blue line in figure 5, the library synchronization completion time was virtually the same for one or two items, suggesting that two items were effectively transferred concurrently. When the number of library items was larger than two, the completion time increased linearly, indicating that the extra file transfers were queued while the network was busy with prior transfers.
With a 10GbE network, we observed a different behavior. The synchronization operations were faster than in the prior experiment, but the network bandwidth was not completely saturated. This was because at a higher transfer rate, the bottleneck was our storage subsystem. This bottleneck became more pronounced as more and more items were synchronized concurrently due to a more random access pattern on the disk subsystem. This resulted in a super-linear curve (red line in figure 5), which would eventually become linear should the network bandwidth become eventually saturated.
The conclusion is that, with a 1GbE network, adding more NICs to the ESX hosts to increase the number of available transfer channels (or alternatively adding more ESX hosts to each site) will increase the total file transfer throughput and consequently decrease the synchronization completion time. Notice that this approach works only if there is constant bi-sectional bandwidth between the two sites. Any networking bottleneck between them, like a slower WAN link, will limit, if not defeat, the transfer concurrency.
With a 10GbE network, unless very capable storage subsystems are available both at the published and subscribed library sites, the network capacity should be sufficient to accommodate a large number of concurrent transfers.
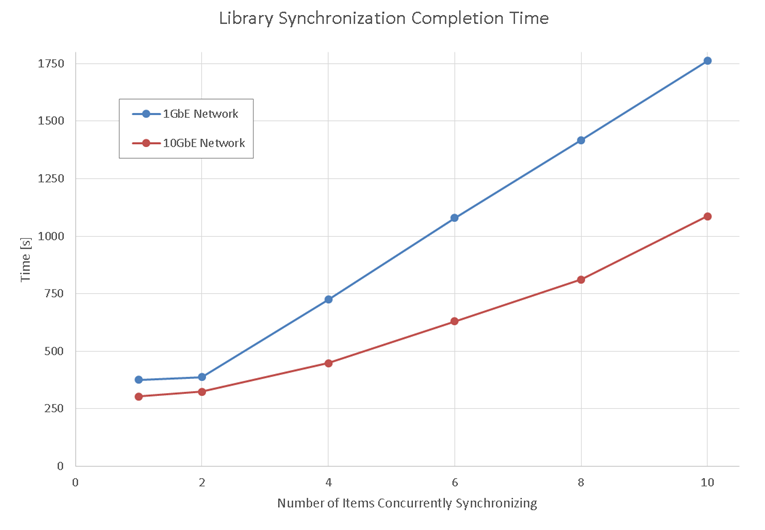
Figure 5. Concurrent synchronization completion times
Library import and export
The Content Library import function lets you upload content from a local system or web server to a content library. Use import to populate a new library or add content to an existing one. The symmetrical export function lets you download content from a library to a local system. Use this function to update content in a library by downloading it, modifying it, and eventually importing it again to the same library.
As for the prior experiments, we studied a few scenarios using different library storage backing and network connectivity configurations to find out which one completed the fastest. In our experiments, we focused on the import/export of a virtual machine template in OVF format with a size of 5.4GB (the VMDK file size was 15GB in uncompressed format). As we did earlier, we assessed the performance impact of rhttpproxy by running experiments with and without it.
We considered the six scenarios summarized here and shown in figure 6.
- Experiment 5: Exporting content from a library backed by a datastore. The OVF template was stored uncompressed using 15GB of space.
- Experiment 6: Exporting content from a library backed by an NFS filesystem mounted on the vCenter. The OVF template was stored compressed using 5.4GB of space.
- Experiments 7/9: Importing content into a library backed by a datastore. The OVF template was stored either on a Windows system running the upload client (Experiment 7) or on a web server (Experiment 9). In both cases, the data was stored in compressed format using 5.4GB of space.
- Experiments 8/10: Importing content into a library backed by an NFS filesystem mounted on the vCenter. The OVF template was stored either on a Windows system running the upload client (Experiment 9) or on a web server (Experiment 10). In both cases, the data was stored in compressed format using 5.4GB of space.

Figure 6. Import/export storage configurations and data flows
Library import and export results
Figure 7 shows the results of the six experiments described above in terms of import/export completion time (lower is better), while the following bullet points summarize the main observations for each experiment.
- Experiment 5: This was the most unfavorable scenario for content export because the data went through the ESX host and the vCenter, where it was compressed before being sent to the download client. Using a 10GbE network or disabling rhttpproxy didn’t help very much because, as we have already observed, data compression was the largest performance limiter.
- Experiment 6: Exporting a library item from an NFS filesystem was the most favorable scenario. The data was already in compressed format on the NFS filesystem, so no compression was required during the download. Disabling rhttpproxy also had a large impact on the data transfer speed, yielding an improvement of about 44%. Using a 10GbE network, however, did not result in additional improvements because, after removing the encryption/decryption bottleneck, we faced another limiter, a checksum operation. In fact, in order to ensure data integrity during the transfer, a checksum was computed on the data as it went through the transfer service. This was another CPU-heavy operation, albeit somewhat lighter than data compression and encryption.
- Experiments 7/9: Importing content into a library backed by a datastore from an upload client (Experiment 7) was clearly limited by the network capacity when we used 1Gbps connections. In fact, the completion time did not change much when we disabled rhtpproxy. Performance improved when we employed 10GbE connections, and we observed further improvements when we disabled rhtpproxy. This suggest that data encryption/decryption was definitely a bottleneck with the larger network capacity. When we used a web server to host the library item to be imported (Experiment 9), we observed a completion time that was more than halved compared to Experiment 7. There are two reasons for this:
- The transfer service bypassed rhtpproxy when importing content from a web server (this is the reason there were no “rhtpproxy disabled” data points for Experiments 9 and 10 in figure 7).
- The web server was more efficient at transferring data than the Windows client VM. Using a 10GbE connection resulted in a further improvement. Given that import performance improved by only 10%, this indicated the presence of another limiter: the decompression of the library item while it was being streamed to the destination datastore.
- Experiments 8/10: When content was being imported into a library backed by an NFS filesystem, we saw a pattern very similar to the one we observed in Experiments 7 and 9. The only difference was that the completion times in Experiments 8 and 10 were slightly better because, in this case, there was no decompression being performed because the data was stored in compressed format on the NFS filesystem. The only exception was the 10GbE Network data point in Experiment 10, which was about 44% better than in Experiment 9. This was because when all the limiters had been removed, data decompression played a more significant role in the import performance.
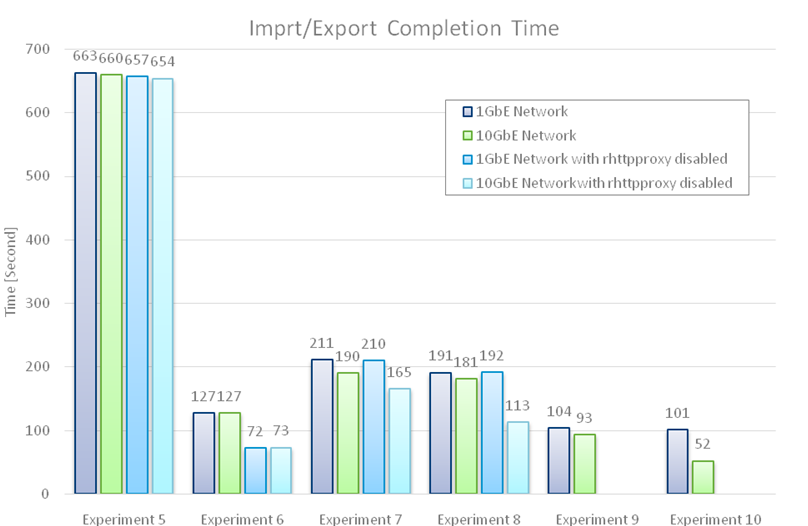
Figure 7. Import/export completion times
Export concurrency
In this last experiment, we assessed the performance of the Content Library in terms of network throughput when multiple users simultaneously exported (downloaded) an OVF template with a VMDK file size of 5.4GB. The content was redirected to a NULL device on the download client in order to factor out a potential bottleneck in the client storage stack. The library backing was an NFS filesystem mounted on the vCenter.
Export concurrency results
Figure 8 shows the aggregate export throughput (higher is better) as the number of concurrent export operations increased from 1 to 10 in four different scenarios depending on the network speed and use of rhtpproxy. When export traffic went through the rhtpproxy component, the speed of the network seemed to be irrelevant because we got exactly the same throughput (which saturated at around 90 MBps) with both the 1GbE and 10GbE networks. This once again confirmed that rhtpproxy, due to the CPU intensive SSL data encryption, createed a bottleneck on the data transfer path.
When we turned off rhttpproxy, the download throughput increased until the link capacity was completely saturated (about 120MBps), at least with a 1GbE network. Once again, you can trade off security for performance by disabling rhtpproxy, as explained earlier.
When a 10GbE network was used, however, throughput saturated at around 450 MBps instead of climbing all the way up to 1200MBps (the theoretical capacity of a 10Gbps Ethernet link). This was because the data transfer path, when operating at higher rates, hit another bottleneck introduced by the checksum operation performed by the transfer agent to ensure data integrity. Generating a data checksum was another computationally intensive operation, even though not as heavy as data encryption.
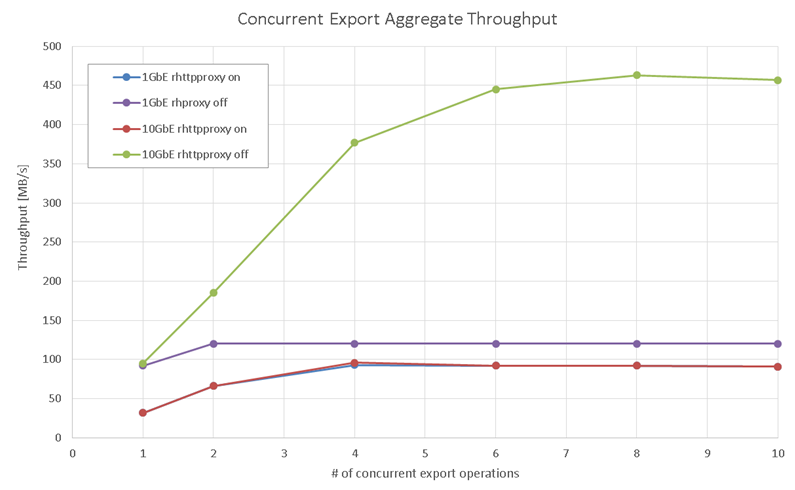
Figure 8. Concurrent export throughput